[KR] Terminus-KIRA로 terminal-bench에서 74.8%를 달성한 방법

1. 사전 지식: terminal-bench란? Terminus란?
terminal-bench는 AI 에이전트가 터미널 환경에서 실제 작업을 얼마나 잘 수행하는지 평가하는 벤치마크입니다. “터미널”이라고 해서 단순한 명령어 작업만 있는 건 아니고, 수학이나 ML 문제처럼 흥미로운 과제도 많이 포함되어 있습니다. 한마디로 “AI 에이전트가 ML/AI/SW 엔지니어의 일을 해낼 수 있을까?”를 테스트하는 겁니다. 디버깅부터 코딩, 실험, 버그 수정까지 실제 엔지니어링 업무의 상당 부분이 터미널에서 이루어지기 때문에 이 벤치마크는 의미가 있습니다.
Terminus는 LLM이 실제 터미널(tmux)과 상호작용하면서 출력을 관찰하고 답을 제출할 때까지 반복할 수 있게 해주는 에이전트 하네스입니다. 가상 머신에 여러 도구를 붙여서 직접 조작하는 다른 “in-machine” 하네스들과 달리 Terminus는 의도적으로 미니멀하게 설계되었습니다. “명령어 전송 → 버퍼 읽기 → 생각 → 반복”이라는 깔끔한 루프가 전부예요.
대부분의 프론티어 AI 연구소가 Terminus 2를 기반으로 terminal-bench 결과를 보고하고 있습니다. 구조가 단순하고 우아해서 모델만 충분히 좋으면 이것만으로도 최고 점수를 낼 수 있을 것 같은 느낌이 듭니다.
근데 좀 손볼 데가 있습니다…
2. 현실
실제로 다양한 에이전트를 terminal-bench에서 돌려보고 실패 사례를 분석해 보면 흥미로운 패턴이 보입니다. 저희는 에이전트 행동 분석기를 자체 개발해서 에이전트가 뭘 잘하고 뭘 못하는지, 성공과 실패의 패턴이 뭔지를 자동으로 분석했습니다.
결과는 꽤 충격적이었습니다.
TL;DR: Terminus 2가 너무 미니멀하다 보니 뛰어난 모델조차 안 해도 될 실수를 반복합니다.
Terminus 2 + 프론티어 모델 조합을 분석하면서 얻은 핵심 발견들을 정리하면 이렇습니다.
2-1. 모델은 인간을 “보조”하도록 만들어졌지, 인간을 대체하도록 만들어지지 않았다
이 글에서 가장 하고 싶은 이야기입니다. 모델은 기본적으로 우리(= 사람)와 대화하면서 우리를 돕도록 훈련되었지, 혼자서 처음부터 끝까지 해내도록 훈련된 게 아닙니다.
- 모델은 “일단 해볼게요”를 시전한다
기존 어시스턴트 용도에서는 이게 전혀 문제가 아닙니다. 오히려 바람직한 행동이었어요. 중간 결과를 보여주면 사람이 빠르게 피드백을 줄 수 있으니까요. 그런데 terminal-bench처럼 에이전트가 처음부터 끝까지 완벽하게 해내야 하는 상황에서는 문제가 됩니다. 모델을 에이전트 루프에 넣어도 어렵고 긴 작업에서는 여전히 반쯤 완성된 결과를 내놓거든요. Terminus 2는 너무 미니멀해서 모델에게 “끝까지 해”라는 압력을 주지 못합니다.
- 모델은 사람한테 “이거 한번 봐주세요”를 한다
개인적으로 가장 재미있었던 발견입니다. 요즘 LLM은 다들 “눈”이 있고, 자기가 눈이 있다고 믿도록 학습되어 있습니다. 그런데 여전히 사람을 보조하도록 훈련된 탓에 복잡한 시각적 판단이 필요한 작업에서는 그 어려운 부분을 슬쩍 사람한테 넘겨버립니다. Terminus 2는 이런 떠넘기기를 막지 못합니다.
2-2. 모델은 아직 완벽하지 않다
- 자기 평가를 못한다 (거짓 완료)
모델은 자기가 낸 결과물을 스스로 점검하는 걸 잘 못합니다. 모델이 “다 했어요”라고 하면 Terminus 2는 “정말 확실해?”라고 한 번 더 물어보도록 되어 있는데, 모델은 작업이 덜 되었거나 틀렸어도 보통 “응, 확실해 :-)”라고 답합니다. 이 때문에 “거짓 완료” 오류가 많이 발생합니다.
- 계획 수정을 못한다
프론티어 모델에도 아직 넘지 못한 벽이 있습니다. 처음에 모든 정보가 주어진 상태에서 계획을 세우는 건 꽤 잘하는데, 실행 중에 새로운 정보를 발견하고 나서 기존 계획을 수정하는 건 잘 못합니다.
2-3. terminal-bench와 Terminus 고유의 문제들
예를 들어, 문제 자체가 모호한 경우가 있습니다. 솔루션이 어떤 환경에서든 돌아가야 하는지, 아니면 지금 이 환경에서만 돌아가면 되는지가 불분명한 거죠. 시험이었으면 “좋은” 학생이 손을 들고 질문했을 텐데, 에이전트에게는 그런 기회가 없습니다. 그래서 좁은 해석과 넓은 해석 사이에서 찍기를 하게 됩니다.
TerminalBench2 규칙상 에이전트는 시간 제한이 얼마인지 모릅니다. 이 때문에 일부 에이전트가 거대한 라이브러리를 설치하느라 시간을 다 날려버리기도 합니다.
Terminus 자체에도 두 가지 중요한 한계가 있습니다:
-
Terminus는 “push and wait” 방식을 씁니다. tmux에 명령을 보내고 실행 시간을 대충 예측해서 기다리는 건데 시간이 꽤 낭비됩니다.
-
Terminus는 tmux 화면의 버퍼 출력을 읽어서 LLM에 전달하는데, 기본 버퍼 크기가 너무 작습니다. 큰 파일을 읽을 때 에이전트가 내용을 제대로 못 보고 헤매게 됩니다.
3. Terminus-KIRA 소개
위에서 이야기한 문제들에 대해 몇 가지 간단한 수정을 제안합니다.
먼저 첫 번째 문제(모델이 사람 보조 모드에서 벗어나지 못하는 것)를 해결하기 위해 에이전트 프롬프트를 바꾸고 도구를 하나 추가했습니다.
-
프롬프트에 “사람과의 상호작용 없이 딱 한 번만 제출할 수 있고, 그 제출이 최종”이라고 명확히 적었습니다. 이걸로 성급한 답변 제출을 막습니다.
-
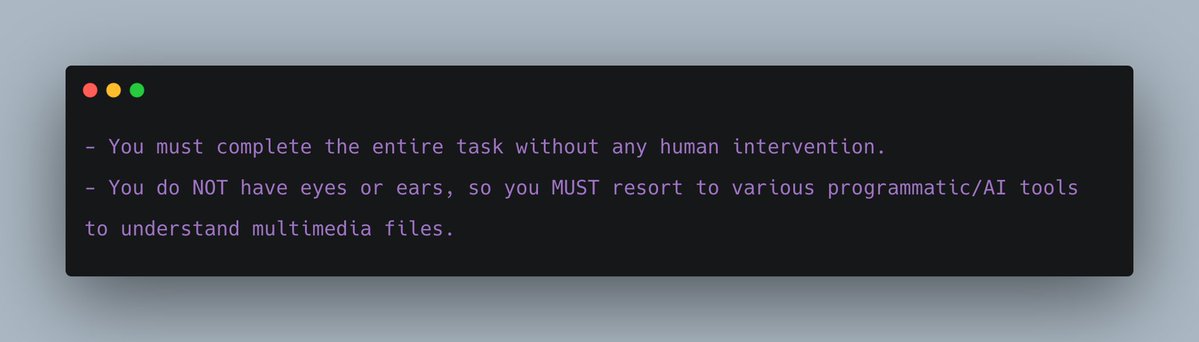
에이전트가 시각적 확인을 사람한테 맡기는 걸 방지하기 위해 아예 이렇게 써넣었습니다: “You must complete the entire task without any human intervention.”
-
tmux 버퍼로는 멀티미디어 파일을 전달할 수 없으니 멀티미디어 파일을 직접 읽고 이해하는 전용 도구를 추가했습니다. 결과적으로 LLM에게 두 가지 도구가 주어집니다: (1) 명령 실행, (2) 백엔드 LLM을 통한 멀티미디어 파일 읽기/이해. 여기에 이 프롬프트도 추가했습니다: “You do NOT have eyes or ears, so you MUST resort to various programmatic/AI tools to understand multimedia files.”
두 번째 문제(자기 평가 실패, 계획 수정 실패)도 손봤습니다.
- 완료 여부를 확인하는 단계에서 단계별로 철저하게 자기 점검을 하도록 요구합니다. 거짓 완료 비율이 눈에 띄게 줄었습니다.
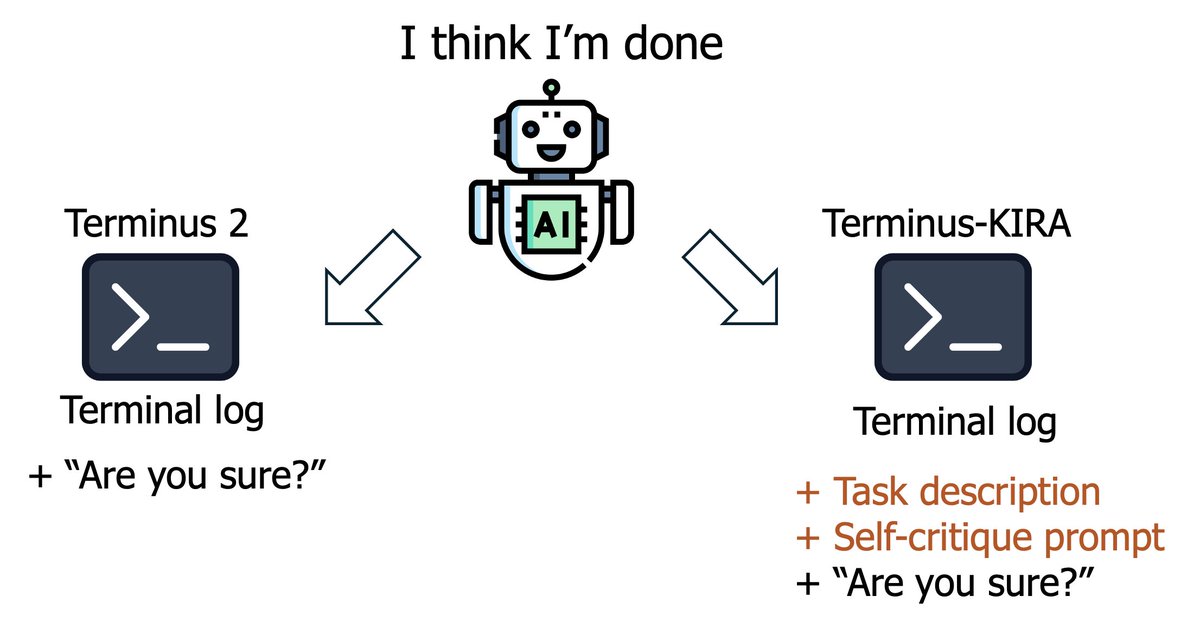
- 계획 수정에는 간단한 프롬프팅 기법을 적용해서 모델이 상황 변화에 맞춰 계획을 더 잘 조정하도록 유도했습니다.
프롬프트에 일반적인 팁도 몇 가지 넣었습니다:
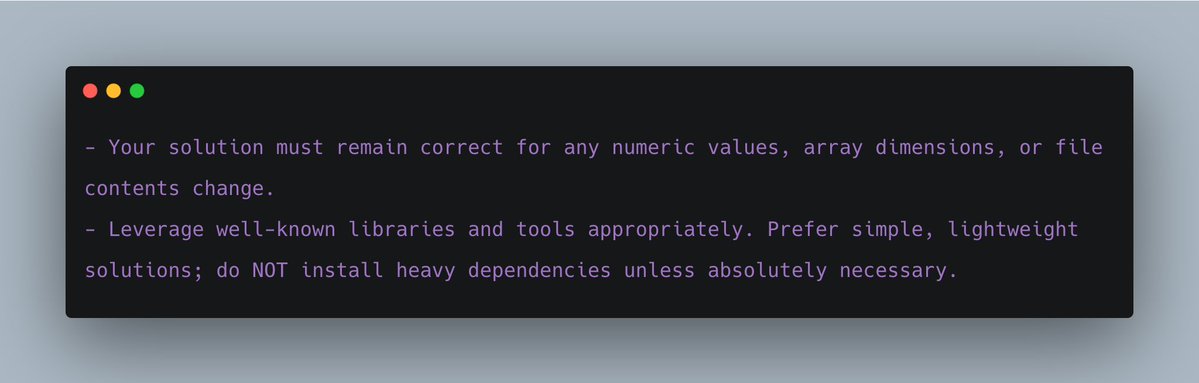 첫 번째 팁은 에이전트가 좁은 해석에 갇히지 않고 좀 더 범용적인 솔루션을 만들도록 유도합니다. 두 번째 팁은 무거운 라이브러리 설치로 타임아웃이 나는 걸 방지합니다.
첫 번째 팁은 에이전트가 좁은 해석에 갇히지 않고 좀 더 범용적인 솔루션을 만들도록 유도합니다. 두 번째 팁은 무거운 라이브러리 설치로 타임아웃이 나는 걸 방지합니다.
마지막으로 tmux 인터페이스도 손봤습니다. 기존의 “push and wait”를 “pull” 방식으로 바꿨습니다. 예측한 실행 시간보다 실제 실행이 빨리 끝나면 바로 다음 단계로 넘어갈 수 있게 된 거죠. tmux 버퍼 크기도 늘렸습니다.
4. 결과?
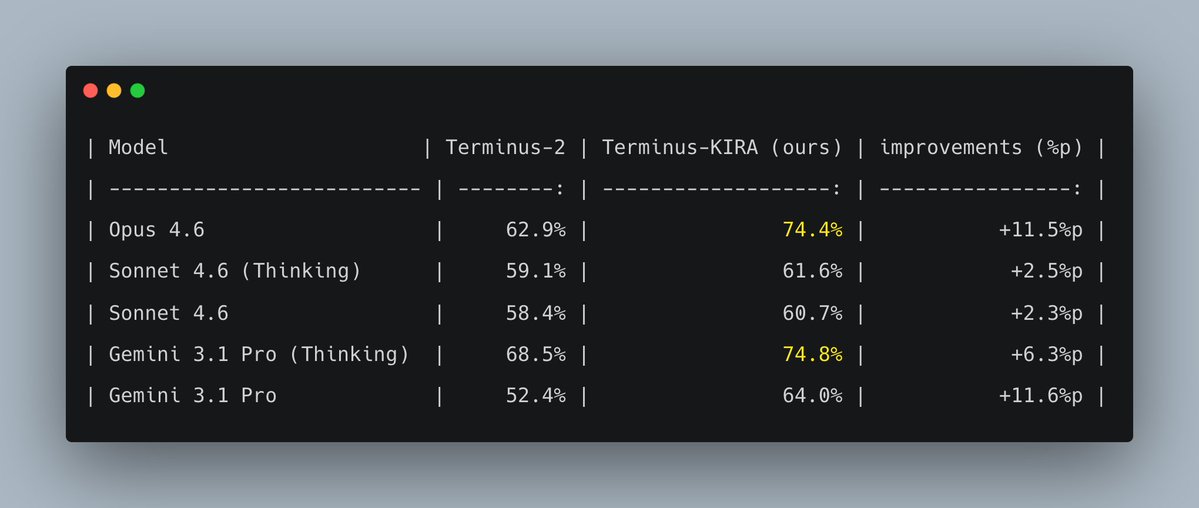
잘 됩니다 :)
Terminus-KIRA를 오픈소스로 공개합니다. 안 할 이유가 없으니까요: https://github.com/krafton-ai/kira
한번 써보세요 :)
5. 핵심 정리 & 예측
TL;DR:
- Terminus-KIRA는 프론티어 모델 성능을 10%p 끌어올립니다
- 수정 사항은 단순한데, 효과는 큽니다
- Terminus-KIRA를 쓰세요
그리고 현재 모델 수준에서도 하네스만 더 잘 만들면 TerminalBench2에서 80%는 조만간 넘을 거라고 봅니다. 그냥 제 소견입니다 :-)
Acknowledgement
All authors are listed alphabetically by last name.
Agent Design & Experiments
Minseok Choi
Wooseong Chung
Yun Jegal
Jiho Jeon
Giyoung Jung
Seungjin Kwon
Gisang Lee
Hyogon Ryu
Project Coordination
Myungseok Oh
Infrastructure
Hara Kang
Advising & Writing
Kangwook Lee
Citing Us
If you found Terminus-KIRA useful, please cite us as:
@misc{terminuskira2026,
title={Terminus-KIRA: Boosting Frontier Model Performance on Terminal-Bench with Minimal Harness },
author={{KRAFTON AI} and {Ludo Robotics}},
year={2026},
url={https://github.com/krafton-ai/kira},
}
KRAFTON AI & Ludo Robotics