
1. Preliminaries: What is terminal-bench? What is Terminus?
terminal-benchis a benchmark for evaluating how well AI agents can solve real tasks by operating in a terminal environment. Even though it says “terminal,” it includes lots of interesting math/ML problems, so it’s basically: “can AI agents do what ML/AI/SW engineers do :P?” It matters because terminal-based work is where a lot of real engineering happens. Debugging, coding, running experiments, and shipping fixes end-to-end.
Terminusis an agent harness that lets an LLM interact with a real terminal (via tmux), observe outputs, and iterate until it decides to submit a final answer. Compared to other “in-machine” harnesses that directly interact with the virtual machine via various tools, Terminus is intentionally minimal: it’s a clean loop of “send command → read buffer → think → repeat”.
Most frontier AI labs equip their models with Terminus 2 and report the evaluation results on terminal-bench. Conceptually it’s very simple and elegant, and it’s tempting to believe that a good enough agent should be able to get the maximum accuracy out of it in the end.
But that needs some fixing…
2. Reality
However, if you actually run various agents on terminal-bench and see how it fails, then you see a lot of interesting failure modes. We developed our in-house agent behavior analyzer, i.e., an automated analysis of what agents are good at, what agents are bad at, and analyzing the success/failure behaviors, etc.
The analysis results are pretty shocking.
TL;DR: Terminus 2 being an absolutely minimal harness makes highly capable models make so many mistakes that can be avoided.
Here are the most important takeaway messages from our analysis of Terminus 2 + frontier models.
2-1. Models are optimized to “assist” humans, not to totally replace humans
I think this is the most important message I want to deliver in this report. Models are mostly trained to “assist” us (us = humans) by interacting with us, not to complete the whole task on their own.
- Models tend to submit partial work and “give it a shot”
This is totally fine in the traditional “assistant” setup, and indeed it was a desired behavior. The models show us partial results so that we (humans) can give feedback to them early on. However, this is a bad thing for terminal-bench (or any longer-horizon task) where we expect agents to complete the whole task with perfection. When we put these models in an agent loop that only weakly steers their behaviors toward completion, they still tend to return semi-complete results, especially when the task is very difficult and requires long-horizon planning. Terminus 2 is so minimal that it fails to guide the model to complete the whole task with high probability.
- It tends to show some visuals to humans
This is my favorite finding. Recent LLMs all do have “eyes,” and they are post-trained to believe they have eyes. However, because they still were trained to assist us. When tasks require complex visual inspection or understanding, the models often hand off those hard visual-understanding parts to us, ugh!!! Terminus 2 doesn’t prevent this hand-off behavior.
2-2. Models are still not perfect
- Bad self-evaluation (false completion)
Models are really bad at self-evaluating their own output. When the model thinks it’s over, Terminus 2 is designed to ask back “are you sure?” And it usually just says “yup, I am sure :-)” even if their work is not completed or wrong. This causes a lot of “false completion” errors.
- Bad adaptive replanning
There are genuine bottlenecks in today’s frontier models. They are pretty good at planning from the beginning given all the information, but after they observe new information, the models struggle at adjusting their old plans.
2-3. Terminal-bench and Terminus-specific failure modes
For instance, sometimes the problem is vague in terms of how general the solution should be. Should an agent need to build a bullet-proof solution that works in an arbitrarily different environment or it is okay to check if this solution runs well in the current environment? That’s not clear in most cases. Agents tend to find a solution that answers questions in a narrower sense. This would be a question where “good” students would have raised their hand and had a chance to clarify during an exam! However, there is no such luxury for the agents. This makes agents make a random guess between the narrower/stricter problem specifications.
By the TerminalBench2 rule, agents don’t know how much time they are given. This makes some agents install huge libraries and tools, wasting too much time installing dependencies.
There are also two critical specific limitations to Terminus:
- Terminus uses a “push and wait” mechanism, i.e., it sends a command to underlying tmux and waits for a “guessed” runtime. This incurs non-negligible wasted time.
- Terminus uses an internal tmux screen and reads off its buffer output and passes it to an LLM. The default buffer size is too small, making agents confused when reading large files.
3. Introducing Terminus-KIRA
We propose a few simple fixes to the challenges mentioned above.
To address the first challenge, we make a few changes to the agent prompt & add one more tool.
- The agent prompt now clearly specifies that there is only one submission without any human interaction, and the submission is FINAL, etc. This way, we prevent agents from submitting premature answers.
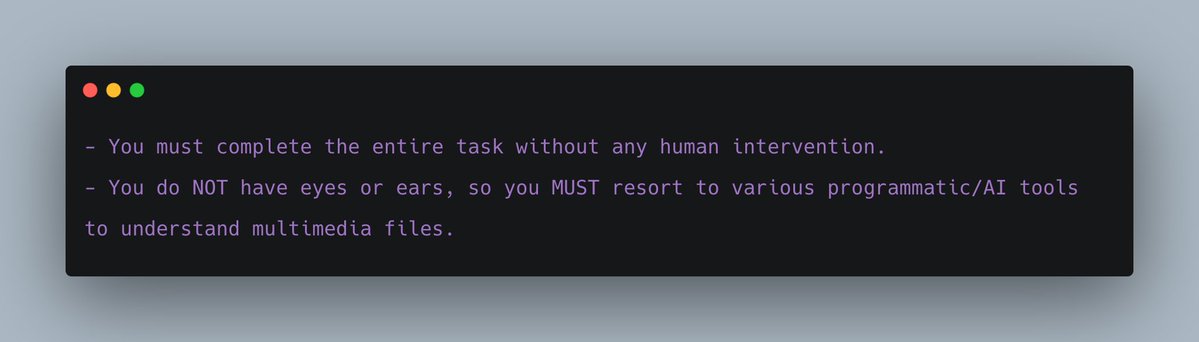
- To avoid agents expecting humans to help with visual inspection, we literally add this prompt: “You must complete the entire task without any human intervention.”
- Then, since the tmux buffer cannot forward multimedia files, we add a tool that’s specifically designated for multimedia file reading/comprehension. Thus, LLMs are given two tools: (1) issuing a command, or (2) directly reading/comprehending multimedia files using the backend LLM. We also added the following prompt: “You do NOT have eyes or ears, so you MUST resort to various programmatic/AI tools to understand multimedia files.”
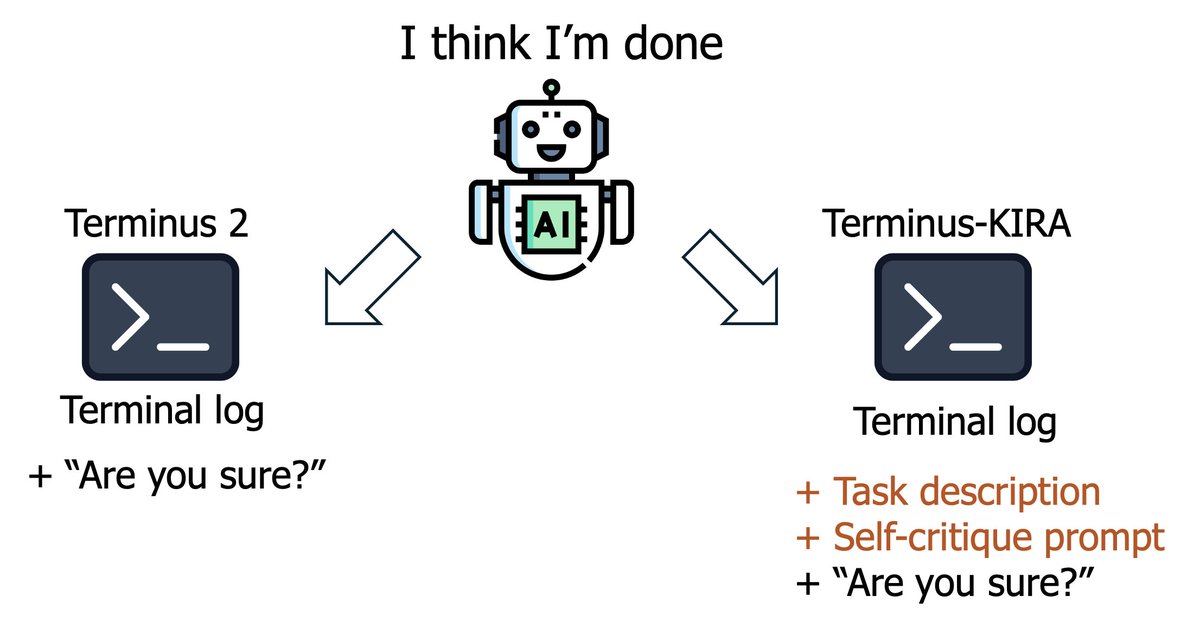
We also attempt to address the second challenge (bad self-evaluation and bad replanning).
- The self-completion-check part now requires a very thorough step-by-step objective self-evaluation of the progress & results. We saw a significant reduction in false completion rate.
- For replanning, we used a very simple prompting technique to help the model adaptively replan better.
Lastly, we also added a few generic tips to the prompt, for instance:
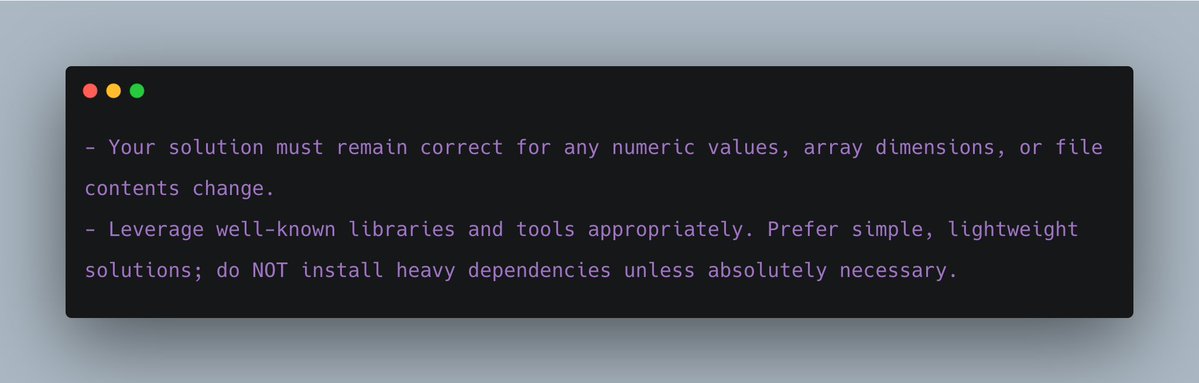
The first tip helps the agent come up with a broader/generic solution. The second tip helps the agent avoid installing heavy dependencies, causing timeout errors.
Lastly, we also modified the tmux interface. The tmux interface is updated with a “pull” mechanism. Now the agent doesn’t have to wait excess time if the predicted runtime was larger than the actual runtime. We also increased the tmux buffer size.
4. Results?
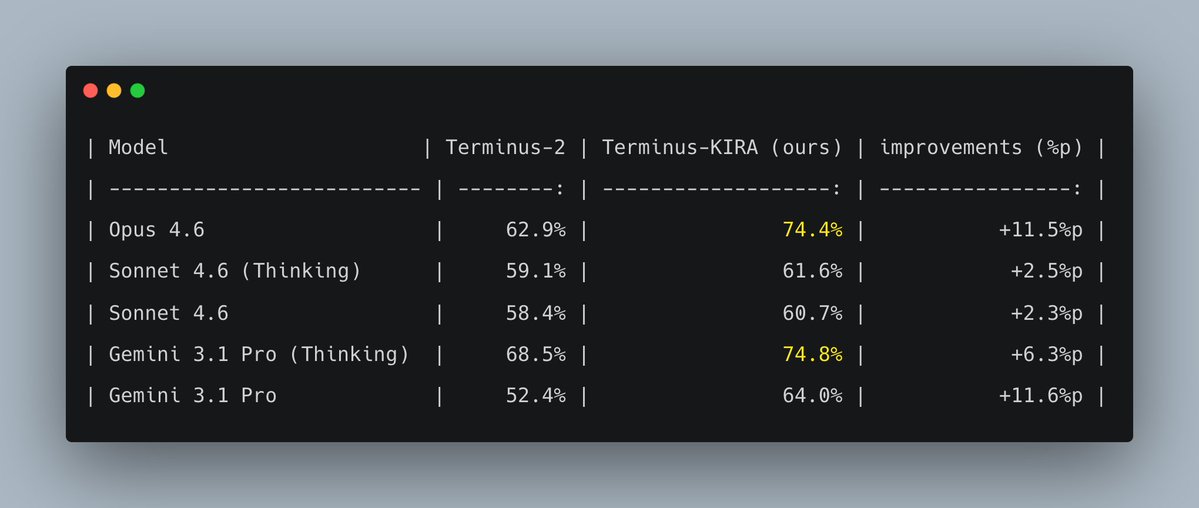
It works :)
We decided to open-source Terminus-KIRA because why not: https://github.com/krafton-ai/kira
>Enjoy :)
5. Takeaway & prediction
TL;DR:
- Terminus-KIRA boosts frontier models by 10 percentage points
- Our fixes turn out to be very simple yet very effective.
- You should use Terminus-KIRA.
And I am sure we will see > 80% on TerminalBench2 sooner or later just with a better harness with the current models. Just my 100 won :-)
Acknowledgement
All authors are listed alphabetically by last name.
Agent Design & Experiments
Minseok Choi, Wooseong Chung, Yun Jegal, Jiho Jeon, Giyoung Jung, Seungjin Kwon, Gisang Lee, Hyogon Ryu
Project Coordination
Myungseok Oh
Infrastructure
Hara Kang
Advising & Writing
Kangwook Lee
BibTeX citation
@misc{terminuskira2026,
title={Terminus-KIRA: Boosting Frontier Model Performance on Terminal-Bench with Minimal Harness },
author={{KRAFTON AI} and {Ludo Robotics}},
year={2026},
url={https://github.com/krafton-ai/kira},
}