Application
We present an example of applying AI ethics to research and services of KRAFTON AI.
Case 1: Generating stylized facial images without gender or racial bias
Background: Bias in generative image models Training generative visual models on biased data or datasets lacking diversity can make the models struggle to accurately represent the full spectrum of human diversity, particularly race and gender. The imbalance in training data is a well-known issue from prior research (Reference : Maluleke, Vongani H., et al. “Studying Bias in GANs through the Lens of Race.” European Conference on Computer Vision (2022)) that often leads to models disproportionately generating outputs that reflect the majority group while omitting or inadequately representing minority groups. Most facial generation models rely on the commonly used training dataset FFHQ, which exhibits extreme bias: 69.2% of the dataset comprises Caucasian individuals, while only 4.2% represents Black individuals. This bias is further exacerbated during inference when techniques to enhance image quality, such as truncation, are applied.
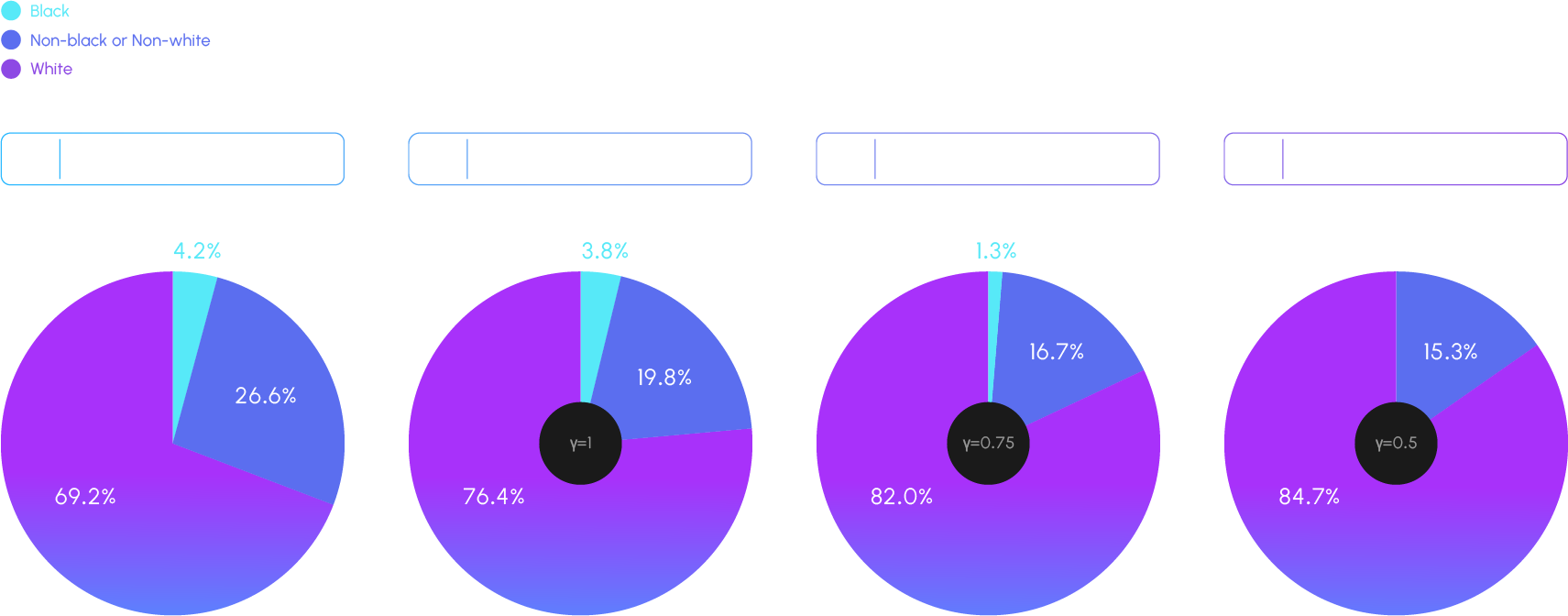
- 1. Image quality: Degraded aesthetic quality in the style transfer results for minority groups
- 2. Identity preservation: The output of style transfer for minority groups resembling the input photo less closely
- 3. Degree of style transfer: Style transfer to and from minority to majority groups converging towards the characteristics of the majority group.
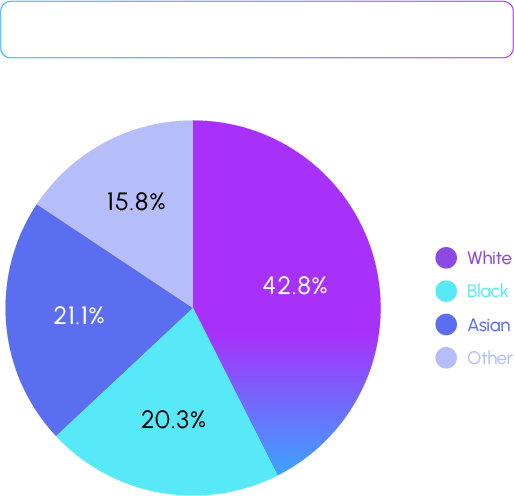
Based on the defined problem, the following criteria were set as benchmarks for evaluating the model. It was observed that using our proprietary dataset for training the model not only reduced the differences in metrics across input/output demographics but also improved overall identity preservation and the quality metrics of the final stylized images. Additionally, to minimize evaluator bias in these metrics, the results from multiple evaluators were standardized through normalization. The study presents a novel approach to addressing the issue of biased datasets, aiming to create fairer AI models that allow people from diverse backgrounds to freely express the full spectrum of race and gender.

Case 2: Toxic Filtering
Classification Criteria

Toxic Filtering Model Training
The toxic filtering model was trained using a Language model. Initially, separate models were developed for a variety of PLMs to evaluate their performance, and then the best-performing language model was selected for further development. Continual tagging was also done based on the criteria established above to enrich the dataset with as much data as possible. After training, precise evaluation is crucial. For this purpose, separate evaluation sets for each case were constructed to assess the model’s performance. The effectiveness of the model was examined for each type of profanity, identifying which types the model handled well and which it did not. The types for which performance was relatively low were targeted for additional data collection to enhance the model’s accuracy and robustness in handling a broader spectrum of offensive content.
Real-world Application
The developed toxic filtering model was applied to conversation data so the data could be processed for use in building a chatbot. When language models are trained directly on data containing inappropriate expressions, they may unintentionally generate such expressions in actual conversations. Therefore, it was necessary to remove these inappropriate expressions from the training data first. The described model was employed to this end. Large-scale data had to be processed quickly, so we implemented distributed processing and inference optimization.
Case 3: PII Filtering
PII (Personally Identifiable Information) refers to information that can directly or indirectly identify an individual. KRAFTON AI is actively engaged in PII filtering across various projects to secure and utilize data without privacy risks. PII filtering is a crucial task aimed at minimizing the risk of personal data breaches and maintaining smooth development and high service quality.
Process
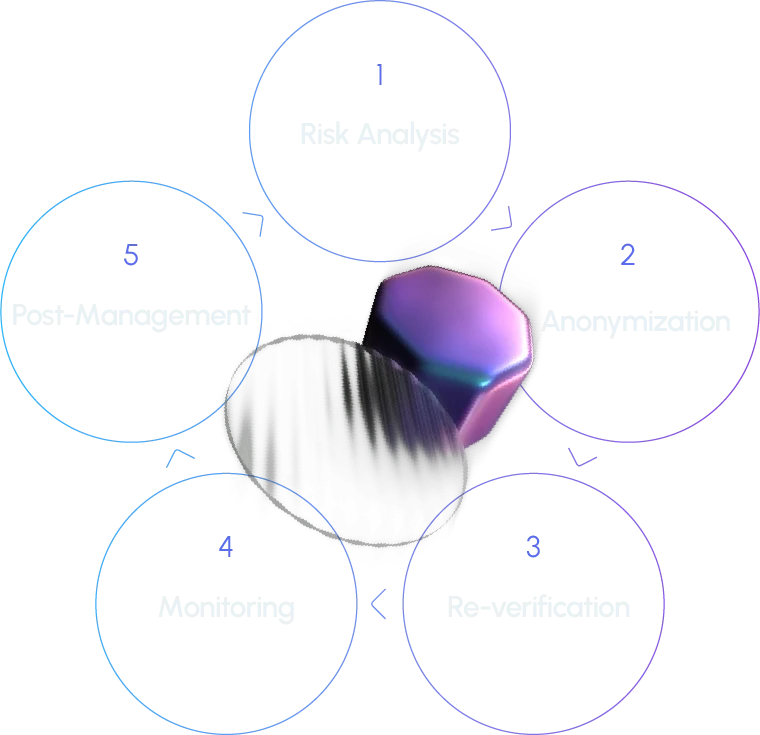
1. Risk analysis: This step involves a review of copyright issues, source verification, inclusion of personal information, and ethics.
2. Anonymization: If this step is applied, an automation tool is used to filter the data. Data loss prevention API is used to detect sensitive information (anonymized by defining 20+ patterns that can help identify an individual) and convert it to tokens predefined internally.
3. Re-verification: The filtered data is cross-checked to verify whether it is fit for deployment.
4. Continuous monitoring: Continuous monitoring is employed to enhance the visibility of risks.
5. Post-management: The data is stored in an access-controlled database with minimal personnel involved.
Additional Measures:
1. When acquiring data externally, we analyze risks using the same criteria (such as verifying the source of open-source data, checking for copyright issues, assessing whether personal information is included, and reviewing ethical concerns). Additionally, we determine whether the data subject’s consent is required or if it is unnecessary.
2. During data collection, we ensure that unnecessary information is not collected and provide guidance to anonymize personal information during the data storage process.
3. For sentences generated by generative models, such as large language models, we perform PII filtering or regenerate outputs to ensure that there are no issues.
4. Data containing personal information is stored in a separate storage accessible only by the data privacy manager, with access restrictions in place. All access to the restricted storage is logged.
In addition to the measures described above, KRAFTON AI has continuously reviewed and improved its current data processing systems based on the expertise of its internal privacy team and regularly ensures compliance with relevant regulations and industry standards.