KRAFTON AI Fellowship 2기 김선우 학생이 1저자로 작성한 논문이 세계 3대 AI 학회 중 하나인 ICLR에 등재되었습니다. 나아가 Spotlight 논문으로 지정되어, 통과된 논문 중에서도 독보적으로 혁신적인 연구 성과를 거둔 것으로 세계의 인정을 받았습니다. 아직 대학을 졸업하지도 않은 학부생이 어떻게 이런 성과를 거둘 수 있었을까요? 김선우 학생과의 인터뷰를 통해 자세한 내용을 들어봤습니다 😊

(사진1) 오늘의 주인공, KRAFTON AI Fellowship 2기 김선우님
Q. 안녕하세요, 간단한 자기소개와 지원 동기에 대해 설명 부탁드립니다.
AI를 공부, 연구 중인 서울대학교 통계학과 김선우입니다. 데이터를 모방하는 것을 넘어 실제 세상과의 상호작용을 통해 발전하는 AI에 관심이 많습니다. 학교 수업이나 책, 온라인 강의 등을 통해 AI에 대해 공부해 오면서 직접 연구를 해보고 싶다는 생각을 항상 가지고 있었습니다. KRAFTON AI Fellowship 은 연구 프로젝트를 리드해 볼 수 있는 기회와 다양한 인적, 물적 (컴퓨팅 리소스) 자원의 아낌없는 지원이 매력적으로 느껴져 지원했습니다. 물론 무척 파격적인 장학금도 결심하게 만든 이유 중 하나였습니다. 😊
Q. AI Fellowship 기간 동안에는 주로 어떤 프로젝트를 진행하셨나요?
AI Fellowship 기간동안 크게 두 가지 프로젝트를 진행했는데요, 초반에는 디퓨전 모델 (Diffusion model) 관련 연구 및 논문 작업을 진행하였고 그 후에는 곧 출시될 KRAFTON의 인생 시뮬레이션 게임, inZOI에 들어갈 AI Feature인 Smart Zoi 프로젝트에 참여했습니다. 디퓨전 모델 연구는 뒤에서 더 자세히 소개 드릴 수 있을 것 같은데요. 간단히 설명하자면 인터넷 데이터로 사전 학습 (pre-train) 되어 생성 질이 높지 않은 모델로 하여금 저희가 원하는 특징의 (예를 들어 프롬프트를 더 잘 따르거나 더 미적인) 이미지를 생성할 수 있게 만드는 생성 기법을 연구했습니다. 두번째로, Smart Zoi 프로젝트는 Small Language Model (SLM)을 활용하는 연구였는데요. inZOI 안에서 캐릭터를 조종하는 on-device AI 에이전트를 개발하는 프로젝트였습니다. 저는 주로 SLM을 이용한 reasoning과 planning고도화 작업을 진행했습니다.

(사진2) ICLR 2025에 Accept된 논문
Q. 처음에 언급하신 연구가 바로 이번에 ICLR에 등재된 논문 내용인 것 같은데요. 조금 더 자세히 설명해 주세요.
맞습니다. “Test-time Alignment of Diffusion Models without Reward Over-optimization” 이라는 연구인데요. 앞서 말씀드린 대로 사전 학습된 디퓨전 모델을 저희가 원하는 특징을 더 잘 따르게끔 만드는, ‘alignment(정렬, 조정)’ 와 관련된 연구입니다. 형식적인 예를 들자면, 저희가 원하는 특징을 얼마나 만족하는지 측정하는 보상 함수 (reward model) 가 주어지고 이 보상을 최대화하는 샘플들을 생성하는 것으로 문제를 적는 것입니다. 기존 방법들은 이를 위해 디퓨전 모델을 추가적인 학습을 통해 fine-tuning 하는데 이 과정에서 reward hacking, 또는 reward over-optimization이라는 ‘편법’을 학습하는 문제가 발생할 수 있습니다. 예컨대 언뜻 보기에 reward 값 자체는 높게 나와도 실제 원하는 형태의 이미지가 나오지 않는 것이죠. 저희가 작업한 논문에서는 fine-tuning 없이 생성 과정에서 reward를 높여 이러한 reward hacking 문제를 완화하면서 추가적인 학습 없이도 더 좋은 결과를 얻을 수 있었습니다.
Q. 기존 연구의 허점을 파고드는 날카로운 연구네요. 이 연구를 진행하신 동기는 뭔가요?
연구를 진행하게 된 동기는 테크니컬한 발견이라고 말씀드릴 수 있을 것 같아요. 사실 기존 fine-tuning 기반 방법에 reward hacking 문제가 존재하다는 것은 이전 다양한 논문들에서도 계속 언급되어 왔습니다. 이 문제에 관해 고민하다 기존의 fine-tuning 기반 방법들의 학습 목적 함수를 수식으로 적고 보니 꼭 최적화 (optimization) 문제가 아니라 추론 (inference) 문제로 접근할 수도 있다는 걸 깨달았습니다. 그렇다면 사전 학습된 모델을 활용하면서 저희가 원하는, 즉 reward가 높은 분포에서 샘플을 생성하기 위해서는 어떤 추론 방법을 사용해야 할까 찾고 고민하다 이번 논문에서 사용한 Sequential Monte Carlo (SMC)을 적용해봐야겠다 생각한 게 연구의 시작점이었습니다.
Q. 막상 아이디어가 떠올라도 그걸 실현하기는 쉽지 않았을 것 같은데요. 연구 과정 중에 어려웠던 점은 없었나요?
연구 과정에서 어려웠던 순간은 크게 세 번 있었던 것 같습니다.
첫번째는 연구 주제를 잡을 때였습니다. 인턴 직전에 학교에서 프로젝트 수업을 들었는데요, 이 때 관심 가는 주제들이 너무 많아 오히려 끝까지 주제를 잡는데 어려움을 겪었고 정작 연구는 길게 진행하지 못했습니다. 이번 KRAFTON AI Fellowship에서는 그런 실수를 하지 않으려고 신경을 썼고, 발산적으로 여러 아이디어를 생각하기 보다는 빠르게 한 주제로 수렴 후 깊게 파보려 노력했습니다. 이 부분에 있어서는 연구 경험이 많은 멘토 분들이 주신 피드백이 정말 큰 도움이 되었습니다.
두번째는 조금 아이러니한데요. 막상 제안된 방법론을 실험해보니 생각했던 것보다도 결과가 훨씬 잘 나오긴 했는데, 저조차 그 이유를 명확히 설명하기 어려웠습니다. 특히 추가적인 학습 없이도 fine-tuning 방법들보다 성능이 좋은 결과는 처음에 믿기 힘들었습니다. ‘결과가 이렇게 잘 나온다’ 라 마무리하고 논문을 낼 수도 있었지만 그러고 싶지는 않았습니다. 이를 설명하기 위해 기존 fine-tuning 방법에서 reward hacking이 발생하는 원인을 수학적으로 접근하였고 간단한 toy example 에서도 실험 결과가 비슷하게 나오는 것을 확인하였습니다. 추가로 제안된 방법이 어떤 이점이 있는지 이론적 증명을 진행했습니다. 처음에 직관적으로 ‘잘 되지 않을까?’ 하고 제안했던 방법을 ‘왜 잘 되는지’ 논리적으로 구체화하는 과정이 어려웠지만 지금 돌이켜 보면 정말 좋은 경험이었습니다.
마지막은 논문 제출 직전 마지막 3주였습니다. 사실 저는 원래 1월에 논문을 제출하려고 생각하고 있었는데요. 연구를 진행하다 보니 어느 정도 윤곽이 잡힌 것 같아 제출을 앞당기게 되었습니다. 그에 따라 마지막에 추가 실험 및 증명 정리, 논문 작성 등 할 일이 정말 많았는데 극복 방법은 결국 정공법이었던 것 같습니다. 3주동안 정말 열심히 살았고 KRAFTON 수면실 (참고로 정말 편하고 좋습니다!)에서 자는 일이 잦았습니다.
첫번째는 연구 주제를 잡을 때였습니다. 인턴 직전에 학교에서 프로젝트 수업을 들었는데요, 이 때 관심 가는 주제들이 너무 많아 오히려 끝까지 주제를 잡는데 어려움을 겪었고 정작 연구는 길게 진행하지 못했습니다. 이번 KRAFTON AI Fellowship에서는 그런 실수를 하지 않으려고 신경을 썼고, 발산적으로 여러 아이디어를 생각하기 보다는 빠르게 한 주제로 수렴 후 깊게 파보려 노력했습니다. 이 부분에 있어서는 연구 경험이 많은 멘토 분들이 주신 피드백이 정말 큰 도움이 되었습니다.
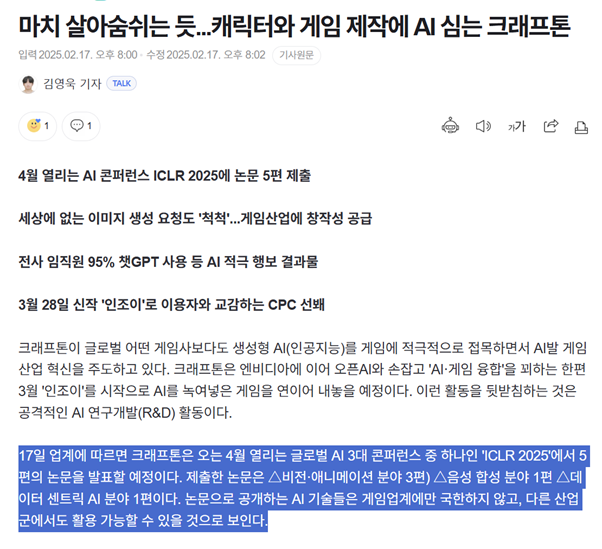
두번째는 조금 아이러니한데요. 막상 제안된 방법론을 실험해보니 생각했던 것보다도 결과가 훨씬 잘 나오긴 했는데, 저조차 그 이유를 명확히 설명하기 어려웠습니다. 특히 추가적인 학습 없이도 fine-tuning 방법들보다 성능이 좋은 결과는 처음에 믿기 힘들었습니다. ‘결과가 이렇게 잘 나온다’ 라 마무리하고 논문을 낼 수도 있었지만 그러고 싶지는 않았습니다. 이를 설명하기 위해 기존 fine-tuning 방법에서 reward hacking이 발생하는 원인을 수학적으로 접근하였고 간단한 toy example 에서도 실험 결과가 비슷하게 나오는 것을 확인하였습니다. 추가로 제안된 방법이 어떤 이점이 있는지 이론적 증명을 진행했습니다. 처음에 직관적으로 ‘잘 되지 않을까?’ 하고 제안했던 방법을 ‘왜 잘 되는지’ 논리적으로 구체화하는 과정이 어려웠지만 지금 돌이켜 보면 정말 좋은 경험이었습니다.
마지막은 논문 제출 직전 마지막 3주였습니다. 사실 저는 원래 1월에 논문을 제출하려고 생각하고 있었는데요. 연구를 진행하다 보니 어느 정도 윤곽이 잡힌 것 같아 제출을 앞당기게 되었습니다. 그에 따라 마지막에 추가 실험 및 증명 정리, 논문 작성 등 할 일이 정말 많았는데 극복 방법은 결국 정공법이었던 것 같습니다. 3주동안 정말 열심히 살았고 KRAFTON 수면실 (참고로 정말 편하고 좋습니다!)에서 자는 일이 잦았습니다.
Q. 정말 고생 많으셨네요. 이 과정 속에서 주변 사람들의 도움이 없었다면 무척 힘들었을 것 같아요. 혹시 김선우님에게 가장 도움을 많이 주었던 KRAFTON에서의 멘토는 누구였나요?
연구는 KRAFTON 딥러닝 본부 Data-centric Research 팀의 민규 님, 동민 님과 함께 진행하였는데요. 협업 과정에서 정말 많은 것들을 배울 수 있었습니다. 좋은 연구를 위해서는 좋은 질문을 해야 한다고 많은 분들이 말씀하시고 저 역시 깊게 동감하는데요, 또 그게 가장 어렵다고도 생각합니다. 멘토 분들께서 제가 가져온 주제들이 어떤 의미와 임팩트를 가질지 함께 고민해주시고 어떻게 스토리텔링을 해야 좋을지 논의해 주셨기 때문에 제가 어떤 문제에 집중해야 할지 정리할 수 있었습니다. 이 부분이 연구 과정 전반에 있어, 그리고 제가 연구자로서 성장하는 데 있어 가장 큰 도움이 되었습니다. 뿐만 아니라 방법론과 실험 설계에 관한 피드백, 논문 작성 및 Rebuttal(논문 반박) 관련 디테일까지 신경 써 주셨습니다. 두 분 덕분에 연구와 논문 작성이라는 좋은 경험을 하면서 성장할 수 있었고 두 분이 아니었다면 ICLR Spotlight이라는 성과는 불가능했습니다.
Q. 고생은 했지만 좋은 분들과 함께 많은 경험을 쌓으며 쓴 논문이라 애정이 각별할 것 같아요. 내 논문에 대해서 자랑도 한 마디 해주세요!
디퓨전 모델의 alignment는 활용될 수 있는 분야가 굉장히 다양합니다. 논문에서 진행한 이미지 생성 관련 실험들뿐만 아니라 단백질 생성 디퓨전 모델에 적용되면 신약 개발에 활용될 수 있고요. 최근 많이 사용되는 Diffusion Policy에 적용되면 로보틱스 분야에도 활용될 수 있을 것입니다. 이러한 맥락에서 기존 alignment 기법들이 reward hacking 문제가 발생하는 원인을 수학적으로 규명하고 이를 해결하기 위해 새로운 test-time 알고리즘을 제안했다는 점에서 향후 디퓨전 모델 alignment 연구들에 도움이 될 것이라 기대합니다. 이러한 기여를 AI 커뮤니티에서도 인정해주어 이번 ICLR에서 Spotlight 발표 기회를 얻게 된 것 같아 기쁩니다.
(사진3) 국내 언론에 소개된 크래프톤 논문 관련 소식 (디지털타임스)
Q. Fellowship에 참여하려고 마음먹었을 때 혹시 이런 결과를 예상했었나요? 아니면 선우님에게도 정말 의외의 소식이었나요?
예상하지 못한 소식이었습니다. Fellowship을 경험하며 예상치 못한 많은 것들을 접했지만, 역시 가장 예상치 못했던 것은 이렇게 빠른 기간 안에 논문을 완성하여 학회에 제출하는 것이었습니다. 연구 경험에 관해서는 이미 앞서 많이 말씀드렸지만 결국 KRAFTON 이 제공해준 환경 덕분에 그렇게 단기간동안 오롯이 연구에 집중하여 제 모든 걸 쏟아 부을 수 있었던 것 같습니다. 그 밖에도 Smart Zoi 같은 대형 회사 프로젝트, 지스타 참관, 팀 워크샵 등 많은 잊지 못할 경험, 추억을 얻었습니다.
Q. Fellowship을 통해 얻은 가장 큰 배움은 무엇일까요?
Fellowship 이후 가장 달라진 것은 연구를 접근하는 방식입니다. 기존에는 연구가 참신한 아이디어를 통해 ‘좋은 방법론’을 찾는 것이라 생각했고 새로운 방법론이 생각나면 그것이 어떤 문제를 해결할 수 있을지, ‘문제를 방법론에 끼워 맞추려’ 했습니다. 이런 습관이 아직 완전히 고쳐지지는 않았지만 이제는 연구에서 가장 중요한 것은 ‘좋은 문제’ 또는 ‘좋은 질문’을 찾는 것이라는 걸 깨닫는 계기가 되었습니다. 연구 과정에서 멘토 분들의 피드백과 더불어 제 연구가 어떤 임팩트를 가질 수 있을지 고민하다 보니 결국 제가 어떤 문제를 풀려는 지가 중요하다는 것을 깨닫았습니다. 이러한 생각의 변화 때문에 이제는 새로운 논문을 읽을 때에도 이 논문이 어떤 방법론을 썼는지에 앞서 어떤 문제를 풀려 하는지를 명확히 파악하려 합니다. 무엇보다도 새로운 연구 주제를 잡거나 장기적인 연구 계획을 세울 때 결국 단기 또는 장기적으로 제가 해결하고 싶은 문제가 무엇인지 고민하게 되었습니다.
Q. 선우님이 연구에 접근하는 방식에 있어서 Fellowship이 긍정적인 영향을 끼친 것 같아 괜히 제가 다 뿌듯합니다. 앞으로는 어떤 계획이나 목표를 가지고 연구를 이어 나갈 계획이세요?
장기적으로는 데이터를 모방하는 것을 넘어 실제 세상으로부터의 피드백을 통해 발전할 수 있는 AI에 관해 연구하고 싶습니다. 몇 년 전부터 언어 및 비전 분야의 대형 모델들은 데이터가 충분하다면 그 데이터를 잘 모방할 수 있음을 증명해냈습니다. 그러나 AI 모델들이 정말 강력한, 또는 파괴적인 힘을 갖는 것은 단순히 데이터를 모방하는 것을 넘어서 새로운 것을 창조할 수 있을 때부터입니다. 이렇게 ‘새로운’ 형태의 데이터는 기존 데이터베이스에 많지 않기 때문에 결국 AI 모델은 실제 세상과의 상호작용 (예를 들어 human preference)을 통해 학습해야 합니다. 이러한 연구는 이미 여러 도메인에서 진행되고 있습니다. 제 연구 주제였던 디퓨전 모델의 alignment, 그리고 최근 언론에서도 보도됐던 DeepSeek-R1 등이 그 예입니다.
그러나 여전히 갈 길은 멉니다. 대형 모델들의 창발적 능력 (emergent ability)에 관한 이해도는 아직 부족합니다. 이대로 점차 AI 모델들의 능력이 발전할수록 안전성에 관련된 문제는 더욱 부각될 것입니다. 반대로 현재 존재하는 방법론들의 한계도 명확하기 때문에 이를 해결해야 AI 모델은 데이터를 모방하는 수준에서 멈추지 않고 끊임없이 발전할 수 있습니다. Fellowship 과정에서 진행했던 연구는 이 과정의 첫 스텝이었다고 생각합니다. 다음 스텝으로는 현재 로봇 학습에 관련된 연구를 진행 중에 있습니다. 로봇 학습 분야에서도 최근 LLM이나 디퓨전 모델의 학습 방법을 활용한 모방 학습 (Imitation Learning) 방법들이 많이 연구되고 있는데요. 데이터의 부족으로 인해 이렇게 사전 학습된 모델은 성능이 떨어지기 때문에 이를 추가 개선하려 합니다. 또 다른 관심 분야는 신약 개발입니다. 신약 개발을 위한 단백질 설계 역시 세상에 존재하지 않는 단백질을 설계해야 하는데요. 애초에 세상에 존재하지 않기 때문에 그 효과를 예측하기 더 어려워집니다. 이를 보완하기 위해서도 현실에서의 실험 등 실제 세상으로부터의 피드백을 잘 활용할 수 있어야 합니다.
Fellowship은 이 여정의 시작점을 제시해주었고 AI의 발전 동향을 더 넓은 시야에서 볼 수 있도록 도와주었습니다. 하지만 무엇보다도 KRAFTON에서의 긍정적인 경험들은 이 여정을 제가 갈 수 있겠다는 자신감을 주었습니다.
그러나 여전히 갈 길은 멉니다. 대형 모델들의 창발적 능력 (emergent ability)에 관한 이해도는 아직 부족합니다. 이대로 점차 AI 모델들의 능력이 발전할수록 안전성에 관련된 문제는 더욱 부각될 것입니다. 반대로 현재 존재하는 방법론들의 한계도 명확하기 때문에 이를 해결해야 AI 모델은 데이터를 모방하는 수준에서 멈추지 않고 끊임없이 발전할 수 있습니다. Fellowship 과정에서 진행했던 연구는 이 과정의 첫 스텝이었다고 생각합니다. 다음 스텝으로는 현재 로봇 학습에 관련된 연구를 진행 중에 있습니다. 로봇 학습 분야에서도 최근 LLM이나 디퓨전 모델의 학습 방법을 활용한 모방 학습 (Imitation Learning) 방법들이 많이 연구되고 있는데요. 데이터의 부족으로 인해 이렇게 사전 학습된 모델은 성능이 떨어지기 때문에 이를 추가 개선하려 합니다. 또 다른 관심 분야는 신약 개발입니다. 신약 개발을 위한 단백질 설계 역시 세상에 존재하지 않는 단백질을 설계해야 하는데요. 애초에 세상에 존재하지 않기 때문에 그 효과를 예측하기 더 어려워집니다. 이를 보완하기 위해서도 현실에서의 실험 등 실제 세상으로부터의 피드백을 잘 활용할 수 있어야 합니다.
Fellowship은 이 여정의 시작점을 제시해주었고 AI의 발전 동향을 더 넓은 시야에서 볼 수 있도록 도와주었습니다. 하지만 무엇보다도 KRAFTON에서의 긍정적인 경험들은 이 여정을 제가 갈 수 있겠다는 자신감을 주었습니다.
Q. 선우님이 KRAFTON에서 경험한 것들에 대해 공유해 주셔서 감사합니다. 마지막으로, 올해 12월에 선우님의 후배가 될 KRAFTON AI Fellowship 3기를 모집할 예정인데요. 지원을 고민하는 후배들에게 하고 싶은 한 마디, 부탁드릴게요.
AI 연구에 관심 있는 학부생에게 AI Fellowship Internship 만큼 좋은 기회는 흔치 않다고 생각합니다. 우선 선발된 모든 Fellowship 분들께 본인이 직접 연구 프로젝트를 리드하거나 관심 있는 프로젝트에 참여할 수 있는 기회가 주어지며 프로젝트 진행 과정에서 경험 많고 뛰어나신 멘토 분들과 협업을 할 수 있습니다. 컴퓨팅 리소스 역시 넉넉히 제공되어 평상시에도 A100 4장까지 사용이 가능합니다! 또 장학금, 월급과 더불어 매일 제공되는 맛있는 식사까지 즐기며 풍요로운 삶을 살며 연구에 집중할 수 있다는 점도 Fellowship 과정 내내 효율적으로 일할 수 있었던 이유 같습니다. 마지막으로, Fellowship 선발 과정 중에 치르는 시험은 정말 높은 퀄리티의 문제들로 엄선해 출제하신다고 들었습니다. 그러므로 선발 과정 자체도 학부생에게는 무척 좋은 경험이 될 수 있으니 관심 있으신 분들은 지원을 망설일 필요가 없어 보입니다!
김선우님의 인터뷰를 통해 KRAFTON AI Fellowship에서 할 수 있는 다양한 경험, 그리고 그 경험을 통한 놀라운 성과까지 엿볼 수 있었습니다. KRAFTON AI Fellowship을 통해 선우님과 같은 멋진 성장을 경험하고 싶은 학부생이 있다면 매년 12월 돌아오는 Fellowship 지원 기회를 놓치지 마시길 바랍니다! 😊
KRAFTON AI Fellowship 소개 및 후기
KRAFTON AI Fellowship 모집 페이지 (매년 12월 오픈됩니다!)
KRAFTON AI 논문 리스트
KRAFTON AI Fellowship 소개 및 후기
KRAFTON AI Fellowship 모집 페이지 (매년 12월 오픈됩니다!)
KRAFTON AI 논문 리스트