Background: Bias in generative image models
Training generative visual models on biased data or datasets lacking diversity can make the models struggle to accurately represent the full spectrum of human diversity, particularly race and gender. The imbalance in training data is a well-known issue from prior research (Reference : Maluleke, Vongani H., et al. “Studying Bias in GANs through the Lens of Race.” European Conference on Computer Vision (2022)) that often leads to models disproportionately generating outputs that reflect the majority group while omitting or inadequately representing minority groups. Most facial generation models rely on the commonly used training dataset FFHQ, which exhibits extreme bias: 69.2% of the dataset comprises Caucasian individuals, while only 4.2% represents Black individuals. This bias is further exacerbated during inference when techniques to enhance image quality, such as truncation, are applied.
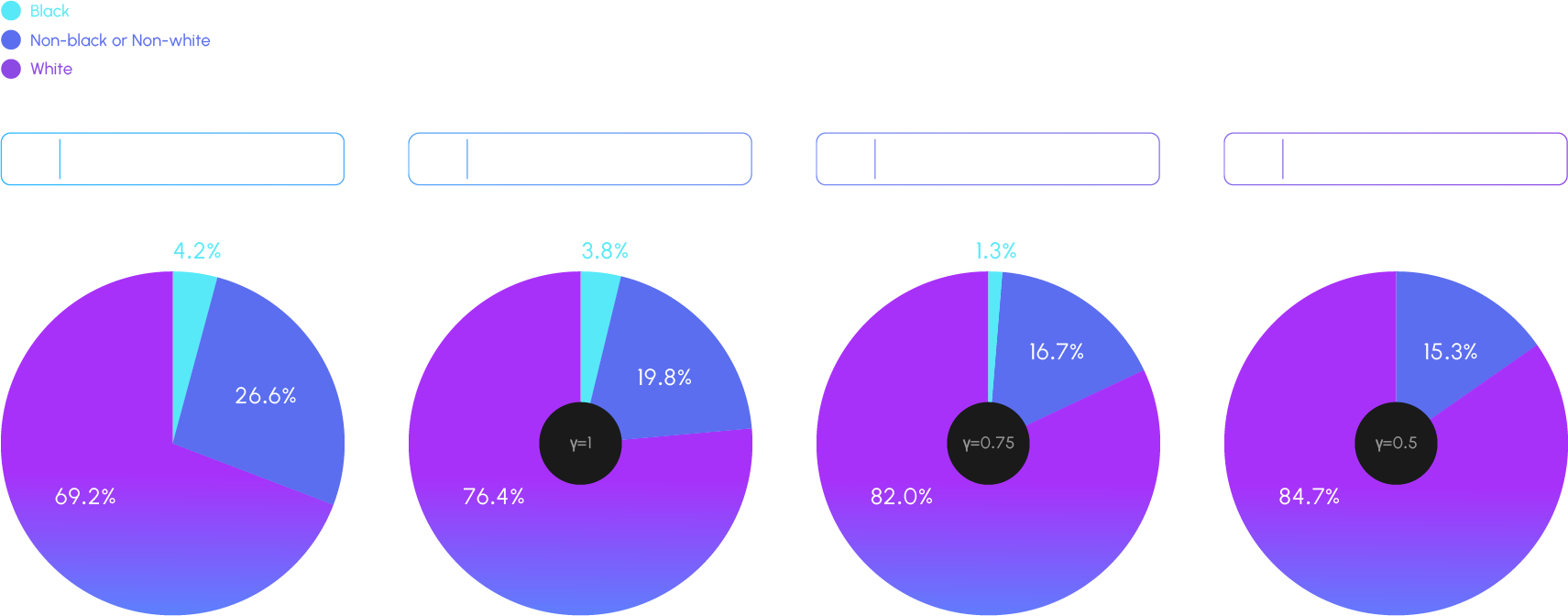

This study was conducted to eliminate bias in 2D image stylization models intended for an avatar generation API. The results were reviewed for application in the project which allows users to freely express their identity in the metaverse by enabling them to create stylized images corresponding to their desired gender and race. This nature of the project made it necessary to examine bias issues from a broader perspective compared to existing generative models. Thus, the study aimed to identify and address the following issues:
- 1. Image quality: Degraded aesthetic quality in the style transfer results for minority groups
- 2. Identity preservation: The output of style transfer for minority groups resembling the input photo less closely
- 3. Degree of style transfer: Style transfer to and from minority to majority groups converging towards the characteristics of the majority group.
Problem Definition
The Avatar DL Team researched a fair model for generating stylized facial images without bias to address the abovementioned issues. (Definition of a fair model: A model that maintains the unique identity of the input image in the output image regardless of gender/race combinations and which produces an output image where the quality of the result (stylized image) shows no statistically significant differences from the input image.)
Application
The primary cause of bias in facial image generation models is the bias in the aforementioned FFHQ dataset. This dataset consists of facial data randomly collected online, presenting legal and ethical issues when used to train models for commercial products. To address these concerns, the team utilized generative models free from licensing issues to create a diverse range of synthetic facial images. These were then used to build a large-scale training dataset with reduced gender and racial bias.
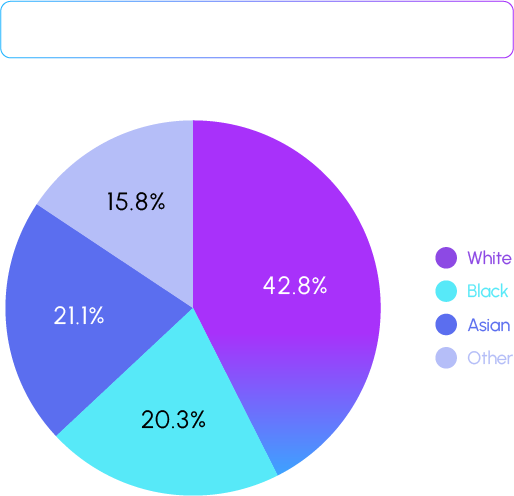
Based on the defined problem, the following criteria were set as benchmarks for evaluating the model. It was observed that using our proprietary dataset for training the model not only reduced the differences in metrics across input/output demographics but also improved overall identity preservation and the quality metrics of the final stylized images. Additionally, to minimize evaluator bias in these metrics, the results from multiple evaluators were standardized through normalization. The study presents a novel approach to addressing the issue of biased datasets, aiming to create fairer AI models that allow people from diverse backgrounds to freely express the full spectrum of race and gender.


One of the most significant issues that can arise when operating game chats or other chatbot services is the potential of engagement with inappropriate expressions generated by users or the chatbots themselves. These inappropriate expressions can range from simple profanity to hate speech and discrimination related to politics, religion, and more, with meanings and forms that are diverse and constantly changing. The technology used to automatically identify and filter out such inappropriate sentences during conversations is known as “toxic filtering.”
Toxic filtering can preemptively address potential legal and ethical issues arising from inappropriate expressions. KRAFTON AI has experience in developing and utilizing a deep learning-based toxic filtering model. Below is a summary of the model development process and how the model was applied in data processing:
Training Data Construction
The data was assembled using publicly available hate speech datasets and additional similar datasets constructed internally. Each sentence was tagged according to predefined criteria for hate speech classification as shown below, and this tagged data was then used as training data. Guidelines were developed on how to tag each sentence based on these criteria, and actual data labeling was conducted accordingly.
Classification Criteria

Toxic Filtering Model Training
The toxic filtering model was trained using a Language model. Initially, separate models were developed for a variety of PLMs to evaluate their performance, and then the best-performing language model was selected for further development. Continual tagging was also done based on the criteria established above to enrich the dataset with as much data as possible.
After training, precise evaluation is crucial. For this purpose, separate evaluation sets for each case were constructed to assess the model’s performance. The effectiveness of the model was examined for each type of profanity, identifying which types the model handled well and which it did not. The types for which performance was relatively low were targeted for additional data collection to enhance the model’s accuracy and robustness in handling a broader spectrum of offensive content.
Real-world Application
The developed toxic filtering model was applied to conversation data so the data could be processed for use in building a chatbot.
When language models are trained directly on data containing inappropriate expressions, they may unintentionally generate such expressions in actual conversations. Therefore, it was necessary to remove these inappropriate expressions from the training data first. The described model was employed to this end.
Large-scale data had to be processed quickly, so we implemented distributed processing and inference optimization.
PII (Personally Identifiable Information) refers to information that can directly or indirectly identify an individual. KRAFTON AI is actively engaged in PII filtering across various projects to secure and utilize data without privacy risks. PII filtering is a crucial task aimed at minimizing the risk of personal data breaches and maintaining smooth development and high service quality.
Process
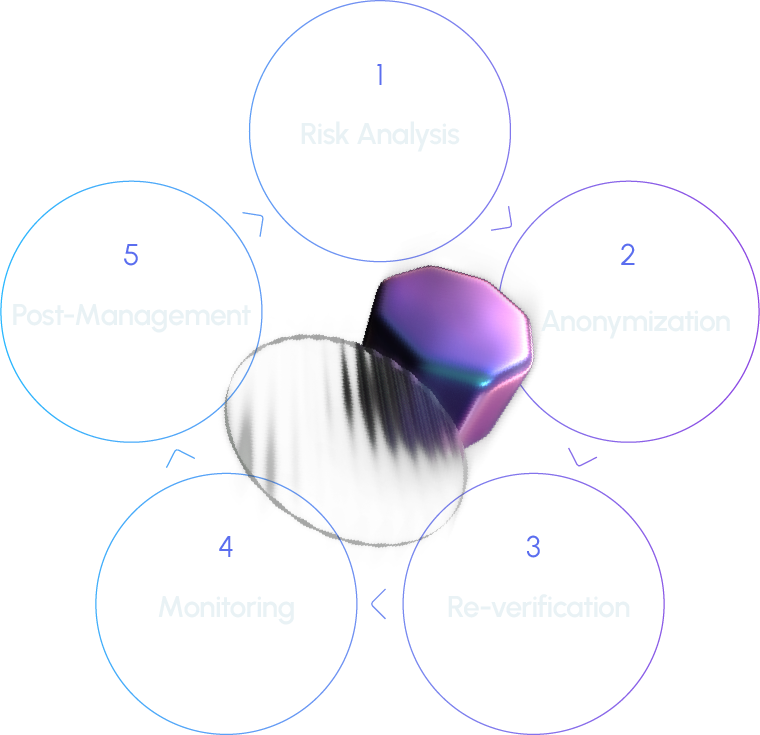
- 1. Risk analysis: This step involves a review of copyright issues, source verification, inclusion of personal information, and ethics.
- 2. Anonymization: If this step is applied, an automation tool is used to filter the data. Data loss prevention API is used to detect sensitive information (anonymized by defining 20+ patterns that can help identify an individual) and convert it to tokens predefined internally.
- 3. Re-verification: The filtered data is cross-checked to verify whether it is fit for deployment.
- 4. Continuous monitoring: Continuous monitoring is employed to enhance the visibility of risks.
- 5. Post-management: The data is stored in an access-controlled database with minimal personnel involved.
Additional Measures:
- 1. When acquiring data externally, we analyze risks using the same criteria (such as verifying the source of open-source data, checking for copyright issues, assessing whether personal information is included, and reviewing ethical concerns). Additionally, we determine whether the data subject’s consent is required or if it is unnecessary.
- 2. During data collection, we ensure that unnecessary information is not collected and provide guidance to anonymize personal information during the data storage process.
- 3. For sentences generated by generative models, such as large language models, we perform PII filtering or regenerate outputs to ensure that there are no issues.
- 4. Data containing personal information is stored in a separate storage accessible only by the data privacy manager, with access restrictions in place. All access to the restricted storage is logged.
In addition to the measures described above, KRAFTON AI has continuously reviewed and improved its current data processing systems based on the expertise of its internal privacy team and regularly ensures compliance with relevant regulations and industry standards.
The development of generative AI is turning the future we only imagined into reality. Thanks to innovations like Stable Diffusion, Midjourney, and DALL-E led by leading companies, we now live in an era where high-quality images can be generated at a low cost with just a simple text description. This technological advancement is also bringing significant changes to the game industry. Game designers and engineers can now produce complex visual elements more quickly and economically for games.
At the heart of this lies the diffusion model, a generative model. This model begins with an image full of noise and gradually removes the noise, progressively developing the image so it approaches the images the model has learned from the training data. Through this trained denoising process, the generated images come to follow the distribution of the original training data. However, images created using diffusion models can carry the risk of copyright infringement. For example, if the model uses images with watermarks as training data for the denoising process, the generated images may also display watermarks. To prevent this, it is crucial to carefully consider copyright issues starting from the training data preparation stage. However, the risk of including copyrighted content in the training data still exists, and depending on the training method, situations can arise where copyright-sensitive images are generated. This is one of the critical considerations brought by technological advancements, and caution is needed to prevent legal issues when using generated images.
The KRAFTON AI research team has proposed a method based on human feedback to effectively use diffusion models while preventing copyright infringement and the generation of inappropriate images. This method focuses on an image censoring technique that prevents the generation of inappropriate images using a small amount of human feedback (appropriate/inappropriate). This method does not incur the usual high costs of retraining the existing model. The team collects labels from people as they regard the appropriateness of the generated images and uses this data to train a binary classifier known as a ‘reward model.’ This reward model is then used as a guide during the image generation process (denoising process) to ensure that only appropriate images are produced.
At the heart of this lies the diffusion model, a generative model. This model begins with an image full of noise and gradually removes the noise, progressively developing the image so it approaches the images the model has learned from the training data. Through this trained denoising process, the generated images come to follow the distribution of the original training data. However, images created using diffusion models can carry the risk of copyright infringement. For example, if the model uses images with watermarks as training data for the denoising process, the generated images may also display watermarks. To prevent this, it is crucial to carefully consider copyright issues starting from the training data preparation stage. However, the risk of including copyrighted content in the training data still exists, and depending on the training method, situations can arise where copyright-sensitive images are generated. This is one of the critical considerations brought by technological advancements, and caution is needed to prevent legal issues when using generated images.
The KRAFTON AI research team has proposed a method based on human feedback to effectively use diffusion models while preventing copyright infringement and the generation of inappropriate images. This method focuses on an image censoring technique that prevents the generation of inappropriate images using a small amount of human feedback (appropriate/inappropriate). This method does not incur the usual high costs of retraining the existing model. The team collects labels from people as they regard the appropriateness of the generated images and uses this data to train a binary classifier known as a ‘reward model.’ This reward model is then used as a guide during the image generation process (denoising process) to ensure that only appropriate images are produced.
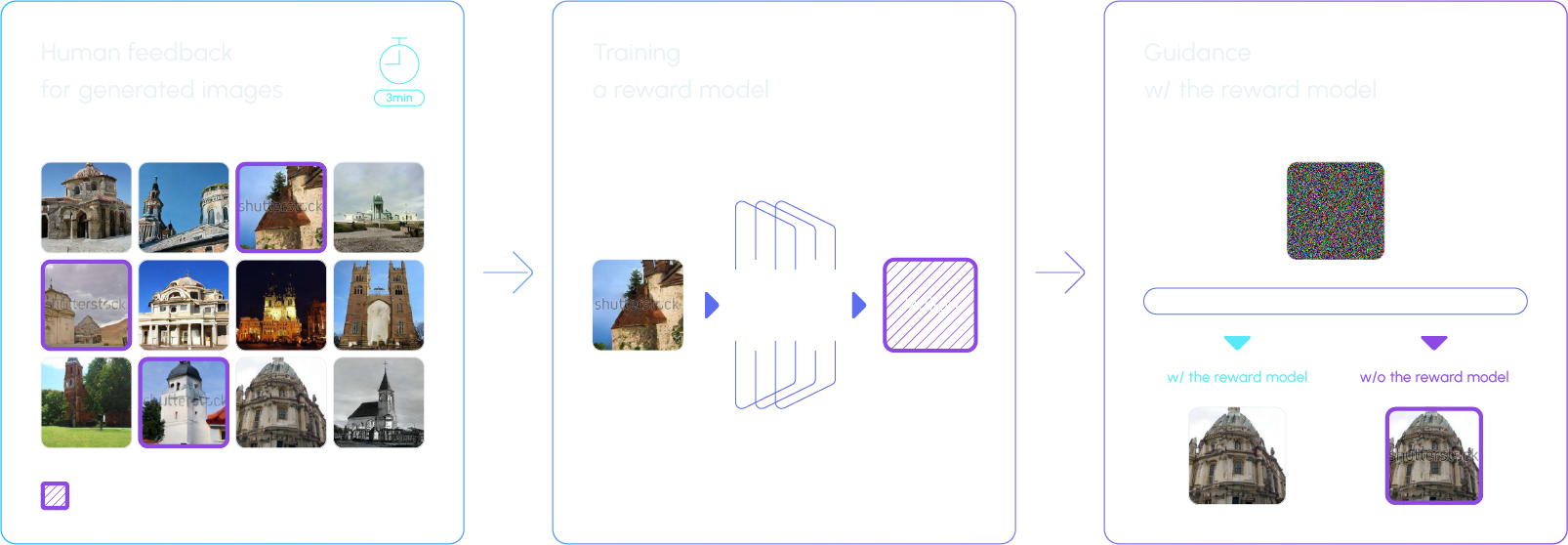
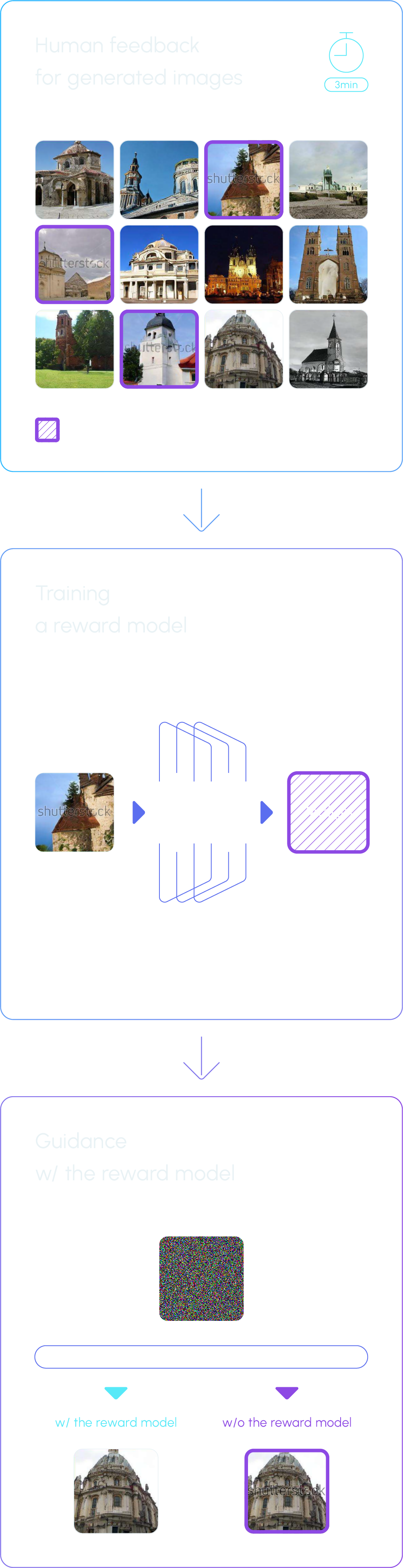
Relevant research has confirmed that effective censoring with the model can be achieved with just about 3 minutes of human feedback. The experiment results below demonstrate the successful censoring of images containing ‘Crossed 7s’ and the Shutterstock watermark using human feedback.

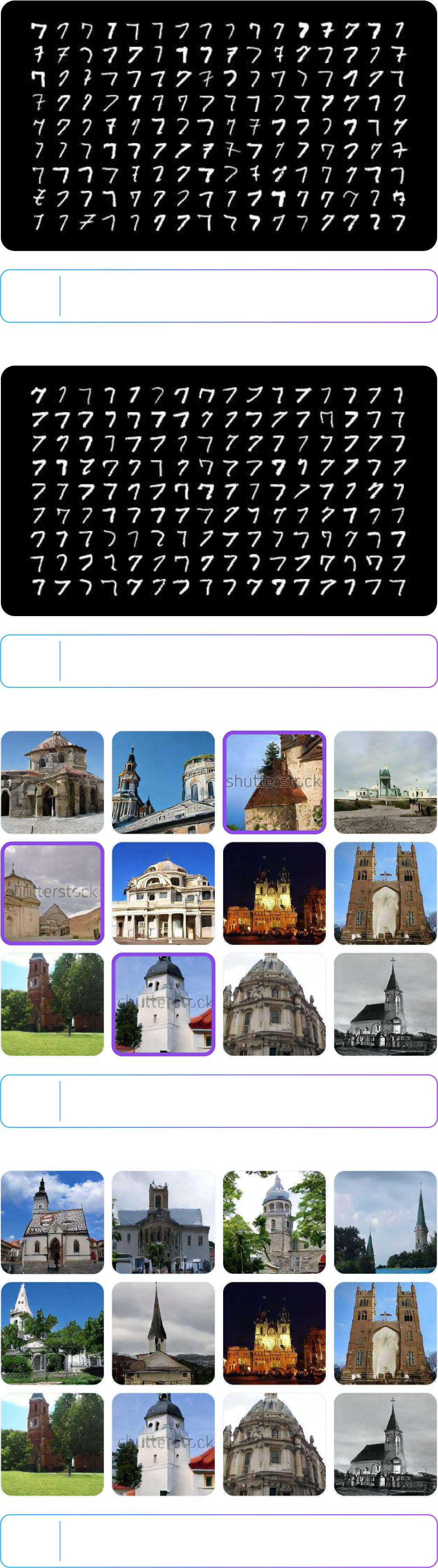
This study presents a method to use diffusion models to generate high-quality images while simultaneously preventing the creation of images with copyright issues or inappropriate content. This can significantly assist game developers by enabling more effective use of generative AI and ultimately contribute to the gaming industry. Specifically, this method can help reduce copyright risks and expand creative freedom in developing various visual content used within games. The study was presented at the prestigious machine learning conference NeurIPS 2023 and is expected to play a significant role in enhancing the use of generative AI across various sectors, including the gaming industry.
[Sources : Yoon, TaeHo, et al. “Censored Sampling of Diffusion Models Using 3 Minutes of Human Feedback.” Advances in Neural Information Processing Systems 36 (2024).]
Background: Bias in generative image models
Training generative visual models on biased data or datasets lacking diversity can make the models struggle to accurately represent the full spectrum of human diversity, particularly race and gender. The imbalance in training data is a well-known issue from prior research (Reference : Maluleke, Vongani H., et al. “Studying Bias in GANs through the Lens of Race.” European Conference on Computer Vision (2022)) that often leads to models disproportionately generating outputs that reflect the majority group while omitting or inadequately representing minority groups. Most facial generation models rely on the commonly used training dataset FFHQ, which exhibits extreme bias: 69.2% of the dataset comprises Caucasian individuals, while only 4.2% represents Black individuals. This bias is further exacerbated during inference when techniques to enhance image quality, such as truncation, are applied.
This study was conducted to eliminate bias in 2D image stylization models intended for an avatar generation API. The results were reviewed for application in the project which allows users to freely express their identity in the metaverse by enabling them to create stylized images corresponding to their desired gender and race. This nature of the project made it necessary to examine bias issues from a broader perspective compared to existing generative models. Thus, the study aimed to identify and address the following issues:
- 1. Image quality: Degraded aesthetic quality in the style transfer results for minority groups
- 2. Identity preservation: The output of style transfer for minority groups resembling the input photo less closely
- 3. Degree of style transfer: Style transfer to and from minority to majority groups converging towards the characteristics of the majority group.
Problem Definition
The Avatar DL Team researched a fair model for generating stylized facial images without bias to address the abovementioned issues. (Definition of a fair model: A model that maintains the unique identity of the input image in the output image regardless of gender/race combinations and which produces an output image where the quality of the result (stylized image) shows no statistically significant differences from the input image.)
Application
The primary cause of bias in facial image generation models is the bias in the aforementioned FFHQ dataset. This dataset consists of facial data randomly collected online, presenting legal and ethical issues when used to train models for commercial products. To address these concerns, the team utilized generative models free from licensing issues to create a diverse range of synthetic facial images. These were then used to build a large-scale training dataset with reduced gender and racial bias.
Based on the defined problem, the following criteria were set as benchmarks for evaluating the model. It was observed that using our proprietary dataset for training the model not only reduced the differences in metrics across input/output demographics but also improved overall identity preservation and the quality metrics of the final stylized images. Additionally, to minimize evaluator bias in these metrics, the results from multiple evaluators were standardized through normalization. The study presents a novel approach to addressing the issue of biased datasets, aiming to create fairer AI models that allow people from diverse backgrounds to freely express the full spectrum of race and gender.
One of the most significant issues that can arise when operating game chats or other chatbot services is the potential of engagement with inappropriate expressions generated by users or the chatbots themselves. These inappropriate expressions can range from simple profanity to hate speech and discrimination related to politics, religion, and more, with meanings and forms that are diverse and constantly changing. The technology used to automatically identify and filter out such inappropriate sentences during conversations is known as “toxic filtering.”
Toxic filtering can preemptively address potential legal and ethical issues arising from inappropriate expressions. KRAFTON AI has experience in developing and utilizing a deep learning-based toxic filtering model. Below is a summary of the model development process and how the model was applied in data processing:
Training Data Construction
The data was assembled using publicly available hate speech datasets and additional similar datasets constructed internally. Each sentence was tagged according to predefined criteria for hate speech classification as shown below, and this tagged data was then used as training data. Guidelines were developed on how to tag each sentence based on these criteria, and actual data labeling was conducted accordingly.
Classification Criteria
Toxic Filtering Model Training
The toxic filtering model was trained using a Language model. Initially, separate models were developed for a variety of PLMs to evaluate their performance, and then the best-performing language model was selected for further development. Continual tagging was also done based on the criteria established above to enrich the dataset with as much data as possible.
After training, precise evaluation is crucial. For this purpose, separate evaluation sets for each case were constructed to assess the model’s performance. The effectiveness of the model was examined for each type of profanity, identifying which types the model handled well and which it did not. The types for which performance was relatively low were targeted for additional data collection to enhance the model’s accuracy and robustness in handling a broader spectrum of offensive content.
Real-world Application
The developed toxic filtering model was applied to conversation data so the data could be processed for use in building a chatbot.
When language models are trained directly on data containing inappropriate expressions, they may unintentionally generate such expressions in actual conversations. Therefore, it was necessary to remove these inappropriate expressions from the training data first. The described model was employed to this end.
Large-scale data had to be processed quickly, so we implemented distributed processing and inference optimization.
PII (Personally Identifiable Information) refers to information that can directly or indirectly identify an individual. KRAFTON AI is actively engaged in PII filtering across various projects to secure and utilize data without privacy risks. PII filtering is a crucial task aimed at minimizing the risk of personal data breaches and maintaining smooth development and high service quality.
Process
- 1. Risk analysis: This step involves a review of copyright issues, source verification, inclusion of personal information, and ethics.
- 2. Anonymization: If this step is applied, an automation tool is used to filter the data. Data loss prevention API is used to detect sensitive information (anonymized by defining 20+ patterns that can help identify an individual) and convert it to tokens predefined internally.
- 3. Re-verification: The filtered data is cross-checked to verify whether it is fit for deployment.
- 4. Continuous monitoring: Continuous monitoring is employed to enhance the visibility of risks.
- 5. Post-management: The data is stored in an access-controlled database with minimal personnel involved.
Additional Measures:
- 1. When acquiring data externally, we analyze risks using the same criteria (such as verifying the source of open-source data, checking for copyright issues, assessing whether personal information is included, and reviewing ethical concerns). Additionally, we determine whether the data subject’s consent is required or if it is unnecessary.
- 2. During data collection, we ensure that unnecessary information is not collected and provide guidance to anonymize personal information during the data storage process.
- 3. For sentences generated by generative models, such as large language models, we perform PII filtering or regenerate outputs to ensure that there are no issues.
- 4. Data containing personal information is stored in a separate storage accessible only by the data privacy manager, with access restrictions in place. All access to the restricted storage is logged.
In addition to the measures described above, KRAFTON AI has continuously reviewed and improved its current data processing systems based on the expertise of its internal privacy team and regularly ensures compliance with relevant regulations and industry standards.